The Surprising Effect of Distance on Download Speed
![]() August 14, 2008 in
HTTP , Optimization
August 14, 2008 in
HTTP , Optimization
Let’s start with a question. What download speed would you expect in this scenario?
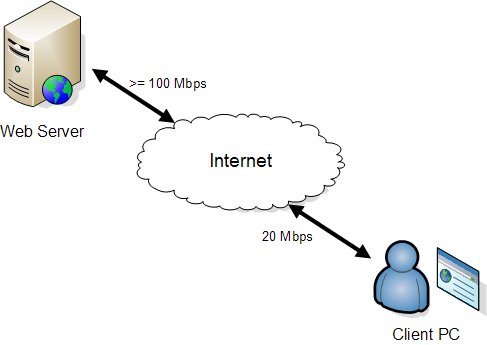
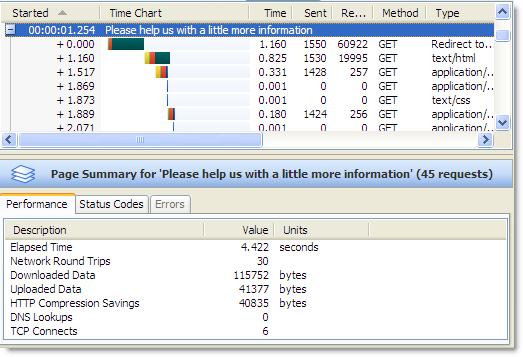
If you just think of network connections as a simple pipe, then you might expect the download speed to be approximately the same as the slowest network connection, i.e. 20 Mbps. When we tested this out using a local UK based website with a ping time of 13 ms we saw this:

The download speed of 1.57 MB /s or 12.56 Mbps (i.e. 1.57 x 8 for 8 bits per byte) was over 60% of the theoretical maximum for the internet connection. That’s quite respectable if you allow you the overhead of the IP and TCP headers on each network packet.
However, the situation was quite different with our own web site that’s located in Dallas. It has a ping time of 137 ms from our office in the UK:
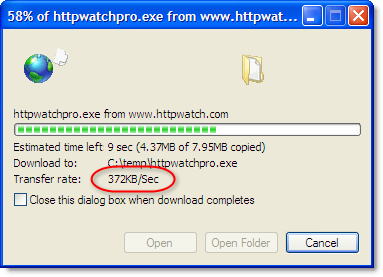
This time the download speed was 372 KB/s or 2.91 Mbps – less than 15% of the advertised internet connection speed.
At first we thought this was some sort of bandwidth throttling of transatlantic traffic by our ISP. However, when we tried using other networks to perform transatlantic downloads we could never get more than about 3 – 4 Mbps. The reason for this behavior became clear when we saw Aladdin Nassar’s talk about Hotmail Performance Tuning at Velocity 2008:
Slide 7 of his talk shows that with standard TCP connections the round trip time between client and server (i.e. ping time) imposes an upper limited on maximum throughput.
This upper limit is caused by the TCP flow control protocol, It requires each block of data, know as the TCP window, to be acknowledged by the receiver. The sender will not start transmitting the next block data until it receives the acknowledgement from the receiver for the previous block. The reasons for doing this are:
- It avoids the receiver getting swamped with data that it cannot process quickly enough. This is particularly important for memory challenged mobile devices
- It allows the receiver to request re-transmission of the last data block, if it detects data corruption or the loss of packets
The ping time determines how many TCP windows can be acknowledged per second and is often the limiting factor on high bandwidth connections as the maximum window size in standard TCP/IP is only 64 KB.
Let’s try putting some numbers into the bandwidth equation to see if it matches our results. For large downloads in IE the TCP window starts at 16 KB but is automatically increased to 64 KB.
So for our remote download test:
Maximum throughput = 8,000 x 64 / ( 1.5 x 137) = 2, 491 Kbps = 2.43 Mbps
This value agrees fairly well with the measured figure. The 1.5 factor in the equation represents the overhead of the IP / TCP headers on each network packet and may be a a little too high explaining some of the difference.
In the past, with dialup connections the maximum throughput value was much higher than the 56 Kbps available bandwidth. But with today’s high bandwidth connections, this limit becomes much more significant. You really need to geographically position your web server(s) or content close to your users if you want to offer the best possible performance over high bandwidth connections.
There are two solutions to this issue but neither is in widespread use:
- IPv6 allows window sizes over 64 KB
- RFC1323 allows larger window sizes over IPv4 and is enabled by default in Windows Vista. Unfortunately, many routers and modems not support it
In the case of interplanetary spacecraft, the round trip time may be colossal. For example, the ping time to Mars can be up to 40 minutes and would limit TCP throughput to approximately 142 bits / sec! With this in mind an interplanetary version of TCP/IP has been designed:
http://www.cs.ucsb.edu/~ebelding/courses/595/s04_dtn/papers/TCP-Planet.pdf
Conclusions
- Distance doesn’t just increase round trip times; it can also reduce download speeds
- Don’t blame your ISP for poor downloads from distant web sites
- Consider using a Content Delivery Network (CDN) or geo-locating your web servers
 There’s a
There’s a