How to check HTTP Compression with HttpWatch
![]() July 10, 2009 in
Automation , C# , HttpWatch , Optimization
July 10, 2009 in
Automation , C# , HttpWatch , Optimization
HTTP compression is one of the easiest and most effective ways to improve the performance of a web site. A browser indicates that it supports compression with the Accept-Encoding request header and the server
indicates the compression type in the Content-Encoding response header.
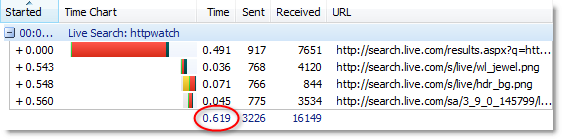
This screenshot from the Stream tab of HttpWatch shows these headers and the compressed content being returned from the server:

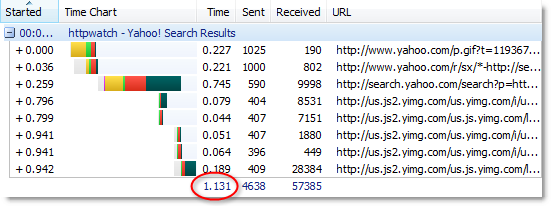
Here’s another screenshot of a page that is not compressed:

The browser still indicated that it accepted gzip and deflate compression, but the server ignored this and returned uncompressed HTML with no Content-Encoding header.
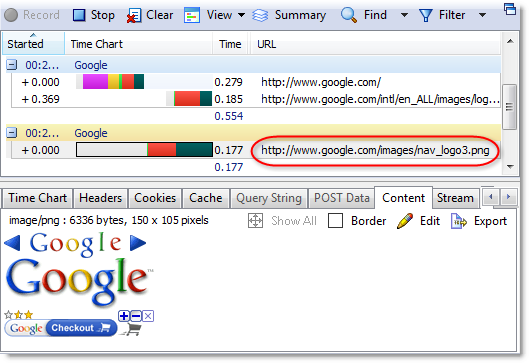
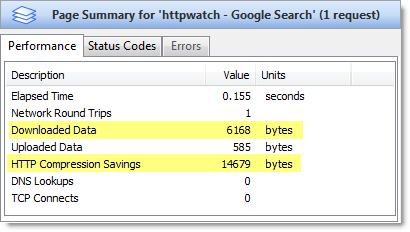
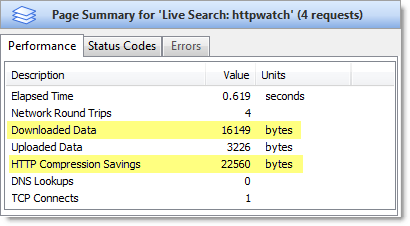
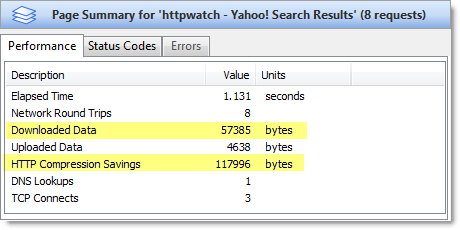
The easiest way to check the amount of compression achieved is to use the Content tab in HttpWatch to view a ‘200 OK’ response from the server:

Don’t try checking for compression on other HTTP status codes. For example, a ‘304 Not Modified’ response will never have any compression saving because no content is returned across the network from the web server. The browser just loads the content fom the cache as shown below:

So, if you want to see if compression is enabled on a page, you’ll either need to force a refresh or clear the browser cache to make sure that the content is returned from the server. The HttpWatch Automation API lets you automate these steps. Here’s an example using C# that reports how many bytes were saved by compressing a page’s HTML:
// Set a reference to the HttpWatch COM library // to start using the HttpWatch namespace // // This code requires HttpWatch version 6.x // using HttpWatch; namespace CompressionCheck { class Program { static void Main(string[] args) { string url = "http://www.httpwatch.com"; Controller controller = new Controller(); // Create an instance of IE (For Firefox use // controller.Firefox.New("") ) Plugin plugin = controller.IE.New(); // Clear out all existing cache entries plugin.ClearCache(); plugin.Record(); plugin.GotoURL(url); // Wait for the page to download controller.Wait(plugin, -1); plugin.Stop(); // Find the first HTTP/HTTPS request for the page's HTML Entry firstRequest = plugin.Log.Pages[0].Entries[0]; int bytesSaved = 0; if (firstRequest.Content.IsCompressed) { bytesSaved = firstRequest.Content.Size - firstRequest.Content.CompressedSize; } System.Console.WriteLine("Compression of '" + firstRequest.URL + "' saved " + bytesSaved + " bytes"); plugin.CloseBrowser(); } } } |
Tip: If you access a web site through a proxy you may not see the effect of compression. This is because some proxies strip out the Accept-Encoding header so that they don’t have to process compressed content. Tony Gentilcore’s excellent ‘Beyond Gzipping’ talk at Velocity 2009 described how 15% of visitors to your site will not receive compression due to problems like this. A simple way to effectively bypass proxy filtering for testing purposes is to use HTTPS if it is available. For example, try https://www.httpwatch.com if you don’t see compression on http://www.httpwatch.com.