Blocked time and IE 8
![]() March 31, 2008 in
HTTP , HttpWatch , Internet Explorer , Optimization
March 31, 2008 in
HTTP , HttpWatch , Internet Explorer , Optimization
A common question we hear from our customers is “What is the Blocked time in HttpWatch and why are we seeing some much of it?”
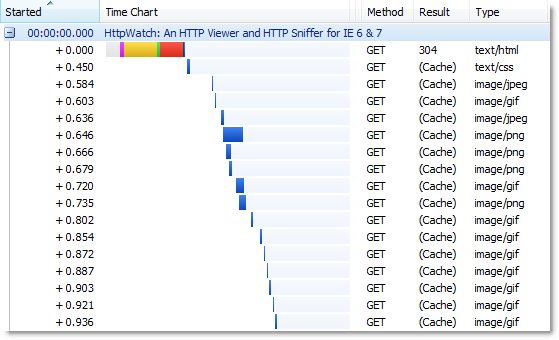
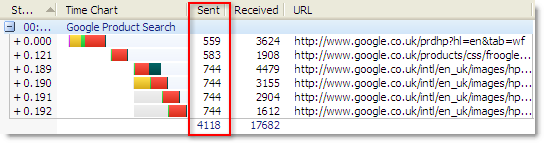
The Blocked time in HttpWatch is shown as a gray block at the start of a request:
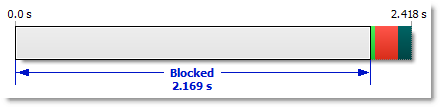
We measure this time by looking at the time interval between these two events:
- The point at which IE determines that it requires the resource at a certain URL. For example, it may have downloaded some HTML and encountered an <img> tag that refers to a GIF file.
- At some later time IE peforms a network action required to download or validate a cached copy of the resource.
During this time interval, IE will check the cache to see if the resource is stored locally, determine what headers and cookies would have to be sent in a GET request to the server, and if necessary, wait for an existing connection to become available.
Although, IE is multi-threaded and could start downloading many resources in parallel it is subject to a connection limit per host name. The HTTP 1.1 specification (RFC2616) recommends that HTTP clients should have no more than two connections active per host name. Therefore, a web page that has all its embedded images, CSS and javascript files on the same hostname (e.g. www.example.com) will only be able to use a maximum of two connections to download content.
Here’s a screenshot from HttpWatch that shows what happens when you force a refresh (Ctrl+F5) of our home page using IE 7:
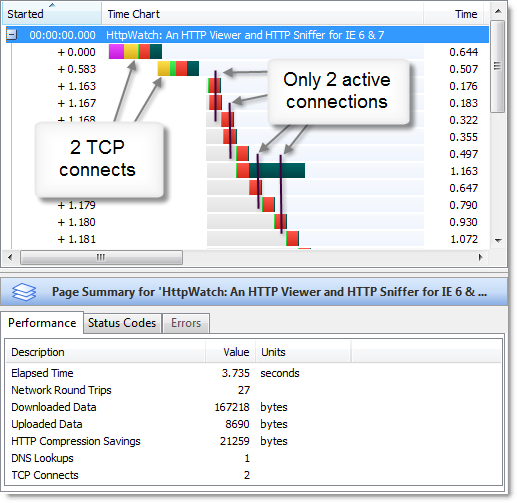
At any one time, only two HTTP requests are actively downloading content. The rest are in the blocked state waiting for their turn to use one of the two connections to the web server. The two yellow segments in the first two requests indicate that two TCP connections were made to the server (a yellow segment in an HttpWatch time chart indicates the TCP connect time).
For many web pages this has a major performance impact and is a strong motivator for reducing the number of round trips whenever possible.
Microsoft has just released IE 8 Beta 1. One of the most significant changes compared to IE 7 is that the maximum number of connections per host name has been changed. If you are on a fast, broadband connection it now uses a maximum of six rather than two connections per host name.
BTW, if you are going to use HttpWatch with IE 8 Beta 1 please make sure that you download and install version 5.3.
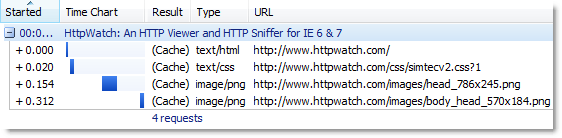
This screen shots shows the six connections being made with IE 8 and the increased concurrency during download:
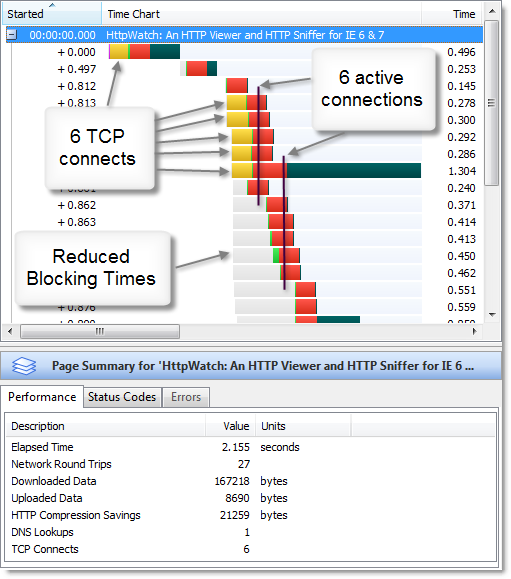
The increase in the number of connections leads to a major reduction in blocked time. We found that the load time for our home page, with an empty cache, is on average 50% less in IE 8 Beta 1 compared to IE 7.
Steve Souders, author of ‘High Performance Web Sites’, has written a blog post entitled ‘Roundup on Parallel Connections’ that discusses the connection limits of other browsers and the possible effect on existing web servers.