Two Simple Rules for HTTP Caching
In practice, you only need two settings to optimize caching:
- Don’t cache HTML
- Cache everything else forever
“Wooah…hang on!”, we hear you say. “Cache all my scripts and images forever?“
Yes, that’s right. You don’t need anything else in between. Caching indefinitely is fine as long as you don’t allow your HTML to be cached.
“But what about if I need to issue code patches to my JavaScript? I can’t allow browsers to hold on to all my images either. I often need to update those as well.”
Simple – just change the URL of the item in your HTML and it will bypass the existing entry in the cache.
In practice, caching ‘forever’ typically means setting an Expires header value of Sun, 17-Jan-2038 19:14:07 GMT since that’s the maximum value supported by the 32 bit Unix time/date format. If you’re using IIS6 you’ll find that the UI won’t allow anything beyond 31-Dec-2035. The advantage of setting long expiry dates is that the content can be read from the local browser cache whenever the user revisits the web page or goes to another page that uses the same images, script or CSS files.
You’ll see long expiry dates like this if you look at a Google web page with HttpWatch. For example, here are the response headers used for the main Google logo on the home page:
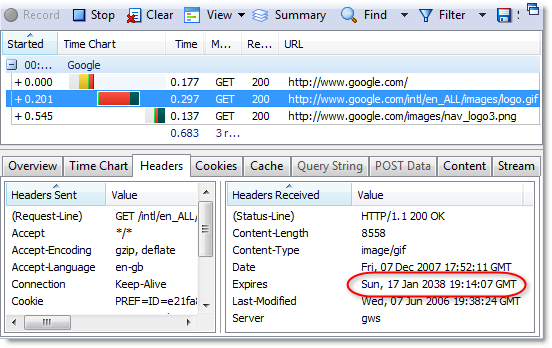
If Google needs to change the logo for a special occasion like Halloween they just change the name of the file in the page’s HTML to something like halloween2007.gif.
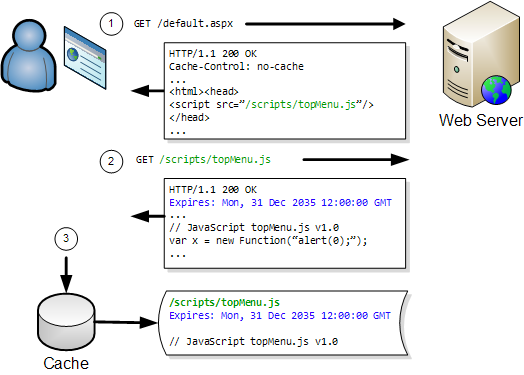
The diagram below shows how a JavaScript file is loaded into the browser cache on the first visit to a web page:
On any subsequent visits the browser only has to fetch the page’s HTML:
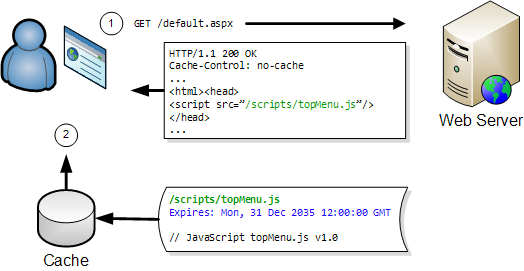
The JavaScript file can be read directly from the browser cache on the user’s hard disk. This avoids a network round trip and is typically 100 to 1000 times faster than downloading the file over a broadband connection.
The key to this caching scheme is to keep tight control over your HTML as it holds the references to everything else on your web site. One way to do this is to ensure that your pages have a Cache-Control: no-cache header. This will prevent any caching of the HTML and will ensure the browser requests the page’s HTML every time.
If you do this, you can update any content on the page just by changing the URL that refers to it in the HTML. The old version will still be in the browser’s cache, but the updated version will be downloaded because of the modified URL.
For instance, if you had a file called topMenu.js and you fixed some bugs in it, you might rename the file topMenu-v2.js to force it to be downloaded:
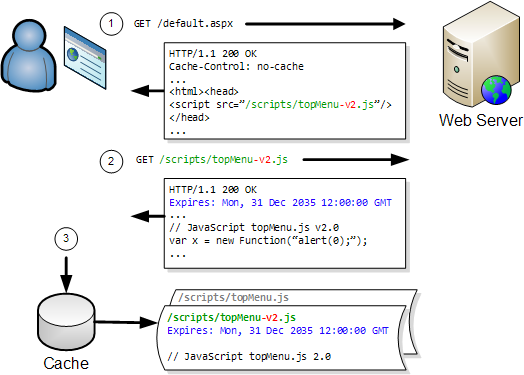
Now this is all very well, but whenever there’s a discussion of longer expiration times, the marketing people get very twitchy and concerned that they won’t be able to re-brand a site if stylesheets and images are cached for long periods of time.
In fact, choosing an expiration time of anything other than zero or infinite is inherently uncertain. The only way to know exactly when you can release a new version to all users simultaneously is to choose a specific time of day for your cache expiry; say midnight. It’s better to set indefinite caching on all your page-linked items so that you get the maximum amount of caching, and then force updates as required.
Now, by this point, you might have the marketing types on board but you’ll be losing the developers. The developers by now are seeing all the extra work involved in changing the filenames of all their CSS, javascript and images both in their source controlled projects and in their deployment scripts.
So here’s the icing on the cake; you don’t actually need to change the filename, just the URL. A simple way to do this is to append a query string parameter onto the end of the existing URL when the resource has changed.
Here’s the previous example that updated a JavaScript file. The difference this time is that it uses a query string parameter ‘v2’ to bypass the existing cache entry:
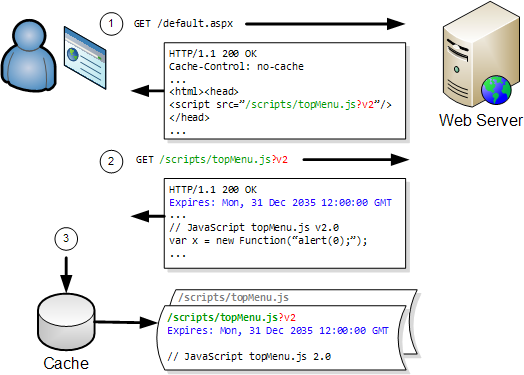
The web server will simply ignore the query string parameter unless you have chosen to do anything with it programmatically.
There’s one final optimization you can make. The Cache-Control: no-cache response header works well for dynamic pages as it ensures that pages will always be refreshed from the server; even when pressing the Back button. However, for HTML that changes less frequently it is better to use the Last-Modified header instead. This will avoid a complete download of the page’s HTML, if it has not changed since it was last cached by the browser.
The Last-Modified header is added automatically by IIS for static HTML files and can be added programmatically in dynamic pages (e.g. ASPX and PHP). When this header is present, the browser will revalidate the local, cached copy of an HTML page in each new browser session. If the page is unchanged the web server returns a 304 Not Modified response indicating the browser can use the cached version of the page.
So to summarize:
- Don’t cache HTML
- Use
Cache-Control: no-cachefor dynamic HTML pages - Use the
Last-Modifiedheader with the current file time for static HTML
- Use
- Cache everything else forever
- For all other file types set an
Expiresheader to the maximum future date your web server will allow
- For all other file types set an
- Modify URLs by appending a query string in your HTML to any page element you wish to ‘expire’ immediately.
The “Cache everything else forever” trick doesn’t seem to work in IE. No matter I do, IE seems to perform a freshness check every time. Any hints/
If you go to Tools->Options->General->Browsing History->Settings in IE 7 is ‘Check for newer versions of stored pages’ set to ‘Automatically’ ?
I disagree!
I have a server that dishes out vehicle images from a large database of several million records. By caching image requests on both the server and the client (for a limited time only) performance is greatly enhanced. The last thing I want is hundreds of clients simultaneously bombarding the server with ever-changing URLs just to make sure they have an up-to-date image. Instead they use the same URL each time for a given vehicle… On the majority of occasions that URL never even makes it out to the internet (because the content is cached on the client) and if hundreds of clients simultaneously request the same image from the server, the server only needs to do its work on the database once (because the content is cached on the server). At the same time, the limited cache duration ensures that the latest image is made available within an acceptable latency period if it does change.
By the way, HttpWatch has been invaluable in making sure that this all works as planned!
Mike,
We’re not advocating using ever changing URLs. What we’re saying is that you only change the URL if your resource/image has changed. In lots of cases images are almost never modified and they should be cached for as long as possible (e.g. Google caches their logo until 2038!). Changing the URL provides a way of forcing a client to update the resource if required.
It sounds like you have a special case where your images are subject to periodic change and it does not matter if your clients have the latest version.
What about cases where a .css or .js has a url embedded in it referencing xxx.jpg? When the xxx.jpg content changes and becomes xxx2.jpg, don’t I now also have to find all of the .css and .js files that reference xxx.jpg, change them to reference xxx2.jpg, rename them to a ver 2 name, find all of the HTML that references those .css and .js files, and change those references as well? Seems like it might be easy to overlook a few references. The downside is that since the original xxx.jpg is still cached in the browser, accessing the page would not produce any error message. It would just show the old image and I’d never realize that customers were getting the wrong image.
Gary,
Yes, that’s right if you changed a jpg you would have to change all references to it and change any references to the CSS or JS files that used it.
It sounds like a lot of work but we tend to find that we rarely change images (usually we just add more) and the image is usually reference in one HTML, CSS or JS file.
Interesting post. Thanks for the advice, I think it’s wise.
*kicks himself for not thinking of this sooner* If only this was the standard operation of webservers. The web would run so much faster. I sorta already knew this in the back of my head as I had done similar things in the past, but you brought it to the front where I needed it. Now I’ll use the technique actively.
I’m creating a mapping website using google maps and custom tiles. I added
header(‘Expires: Sun, 17 Jan 2038 19:14:07 GMT’);
and
header(‘Cache-Control: public’);
as well as a version number to my tile urls and everything just flies now! I also don’t have to worry as much about huge bills from the tile requests (well at least not as much, still looking into getting this working with amazon s3).
Thanks again for the logic slap.
Good Post,
Canu u plz tell how to cache Only css,js,img , not html Page.
Ripal,
You would need to set the Cache-Control header separately for these resources.
One way to do this is to put them in separate folders, e.g. /css, /js, etc. In a web server like IIS you can then set the Cache-Control header at the folder level through the IIS Admin applet.
Very good post!.No other website explained caching with such diagrams and crystal clear explanation.Thanks a lot.Great Effort.
You could also write a handy PHP script for all of your static resources that automatically track changes which would automatically append a different query string so clients would either use their cache or get the new one (all automatic).
How do you set “Cache-Control: public” to a single folder/file on IIS6?
Kevin,
In the IIS Manager go to Properties of the folder/file and setup Cache-Control as a custom header
i still don’t understand anything.
if i use just a plain .html file, what then?
Where do i write ‘no-cache’ code?
in a separate default.aspx file?
I cannot do it in html: “Cache-Control: no-cache” is not html language. And all i know is html.
what am i missing?
Ziggy,
Yes, the HTTP response headers are separate from the HTML. You would need to set them for static files in IIS or whatever web server you are using.
With dynamically generated content (e.g. ASPX) you can specify the headers programmatically.
If you would, please help to confirm my config.
Site: growth trac dot com
Site-wide, we’re using this:
Our pages are *.php — mostly static with some dynamic elements.
QUESTIONS
— Do we need to use a Last-Modified header?
— Do the above settings look “okay” ?
Also —
I’ve read different opinions on the use of
“max-age” vs “expires”
Some say: use both or use the “max-age” (more reliable?)
— What do you say?
Thanks for an excellent article.
Jim,
The last paragraph of the post explains why Last-Modified should be provided if possible.
The images on your site have an appropriate Expires header, but you haven’t set Expires for many of the CSS and Javascript files.
Great… Nice with pictorial representation
Generally good, but it would probably be better to set a max-age of a minute or ten for HTML.
“no-cache” does not mean that back/forward will hit the server. RFC2616 explicitly says back/forward is exempt from cache expiration.
Also, you need not send a Last-Modified date in order to allow for conditional validation: an ETAG will also allow that.
More clear description with the flow of working mechanism… Good Work.. Good Effort. Thanks
I have the question that, If the set the EXPIRE header to future date. For ex : 01-01-2030 … In between i changed the source file and i want to access the modified sources without changing the url. How this is possible? Please guide me.
If you change a resource with a long expiration date you would have to change the URL. Otherwise, browsers may use the previously cached version of the resource.
I know this is an old article but you say to set an Expires header to “Sun, 17-Jan-2038 19:14:07 GMT”. Going by the HTTP/1.1 spec this is not valid* as “HTTP/1.1 servers SHOULD NOT send Expires dates more than one year in the future” so this should be set to aprox. 1 year in the future.
Setting this so far in advance may have adverse effects for browsers and caches who strictly implement the spec as they may reject this request as invalid and not cache the resource.
Tom
* http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.21
Tom,
According the language definition in the spec ‘SHOULD NOT’ means not recommended:
“4. SHOULD NOT This phrase, or the phrase “NOT RECOMMENDED” mean that
there may exist valid reasons in particular circumstances when the
particular behavior is acceptable or even useful, but the full
implications should be understood and the case carefully weighed
before implementing any behavior described with this label.”
If it was disallowed the spec would have used ‘MUST NOT’. Far futures expires of more than one year are fairly widely used and we’re not aware of any problems triggered by a value more than one year into the future.
Understanding that this post is a older one, I’m guessing the best practices for expirations of cacheable content has changed. Most people have switched to Max age and used 1 year as that is the max defined in the RFC like this: cache-control:private, max-age=31536000
I’ve been wondering on what the impact is with the different browsers if people set content longer than what the RFC states, will it become evicted from the browser side cache sooner because of this?
RFC:
Historically, HTTP required the Expires field-value to be no more
than a year in the future. While longer freshness lifetimes are no
longer prohibited, extremely large values have been demonstrated to
cause problems (e.g., clock overflows due to use of 32-bit integers
for time values), and many caches will evict a response far sooner
than that.
super cool post! Huge help! Thank you.