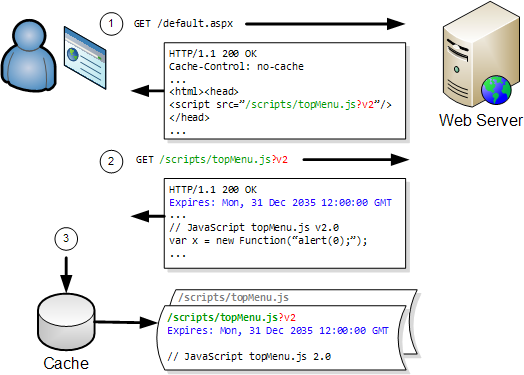
The Performance Impact of Uploaded Data
![]() January 18, 2008 in
Caching , HTTP , HttpWatch , Optimization
January 18, 2008 in
Caching , HTTP , HttpWatch , Optimization
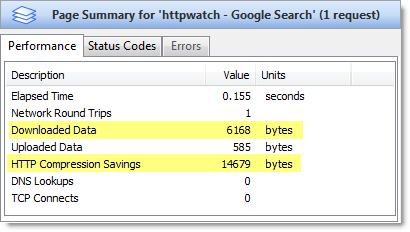
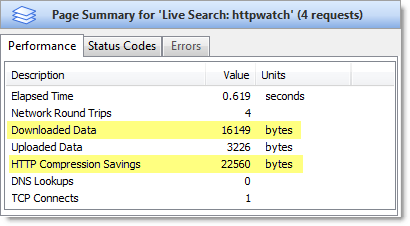
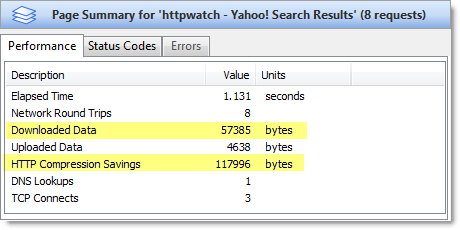
Web developers are becoming more aware of the performance penalties of page bloat and as we covered in our previous posts there are ways to mitigate this, compression being just one.
However, one of the causes of poor performance that is often overlooked is the transmission time taken to upload data to the server. Although, HTTP request messages are typically smaller than HTTP response messages, the performance cost can be an order of magnitude higher per byte. This is caused by the asymmetric nature of many consumer broadband connections.
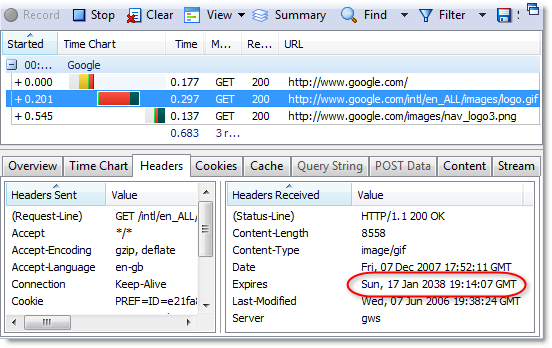
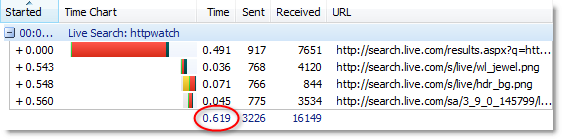
For example, the results of a speed test on a UK broadband cable connection are shown here:
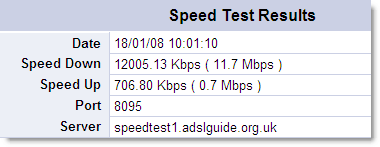
The upload speed is only about 6% of the download speed. That means, byte for byte, uploaded data takes about 16 times as long to transmit as the equivalent amount of downloaded data.
To put it another way, if you upload 4 KB of data in an HTTP request message it may take the same length of time as downloading a 64 KB page.
You can easily see the size of the HTTP request message by looking at the Sent column in HttpWatch:
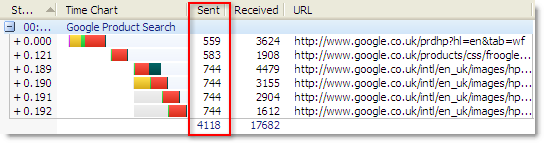
The value shown in the Sent Column is made up of the size of the following items:
- The HTTP GET or POST request line
- HTTP request headers
- Form fields and uploaded files sent with POST requests
Unfortunately, request data is never compressed because there is no server-side equivalent of the Accept-Encoding request header that is used by browsers to indicate that they support compression of downloaded content.
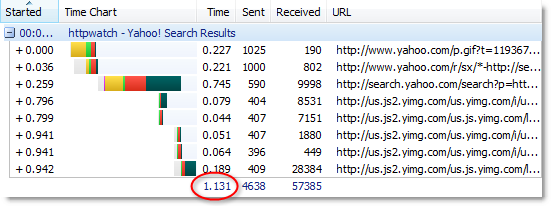
For a typical site, you might be surprised to know that the request data can be up to 50% of the size of the response data. Since many broadband connections are asymmetric, this can have a substantial impact on performance. Here’s an example of a flight search page on Expedia:

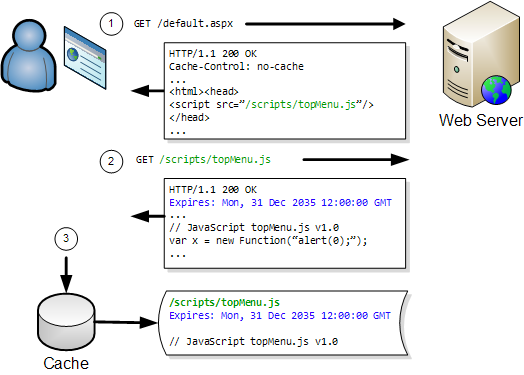
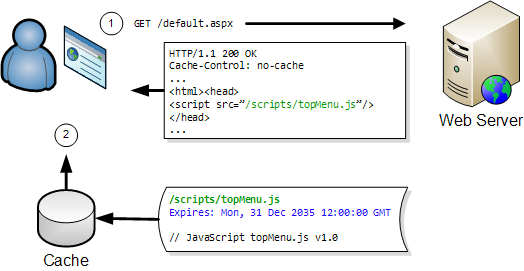
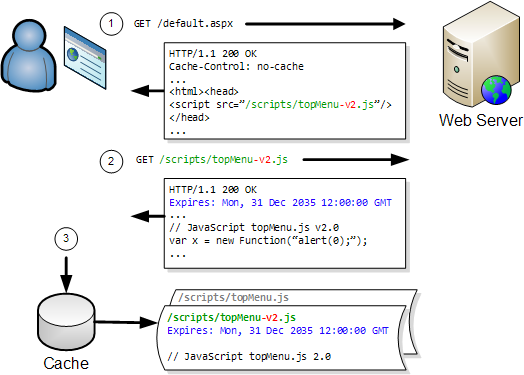
The ratio increases as the downloaded content is cached by the browser, often making uploaded data the most significant factor in the performance of a web page.
So what can be done to reduce the amount of uploaded data?
Step 1: Minimize the size of Cookies
Cookies are simply part of the request headers. Expedia uses around 9 cookies which are fortunately quite small but it’s easily possible to end up with a lot of cookie data, particularly if you’re using 3rd party web frameworks. RFC2109 specifies that browsers should support at least 20 cookies for each domain and at least 4K of data per cookie.
The problem with cookies is that they need to be sent with every single HTTP request where the URL is in the domain and path to which they apply. That includes requests for style-sheets, images and scripts. So in most cases the amount of cookie data uploaded, is effectively multiplied by the number of requests per page.
One way to reduce the amount of cookie data (apart from making them as small as possible and using them less) is to use different domains or paths for your content. For instance, you probably need cookies in your page processing code but you don’t need them for static content such as images. If you put static content in a different location, cookie data will not be sent because cookies are domain and path specific.
Another way to reduce cookie data is to look at server-side storage, such as using the session state management of a framework like ASP.NET. You can then use a single cookie that just contains a session id and look up any session related data on the server when required. Of course, this may have an impact on server side performance, but it is a useful way of minimizing the amount of cookie data that a site requires.
Step 2: Avoid Excessive use of Hidden Form Fields
There are two sets of data in a typical HTML form:
- Fields you want the user to fill out with information.
- Hidden fields.
You can’t really do much about the first type, except reducing the size of your field names. This may be difficult depending on your implementation framework.
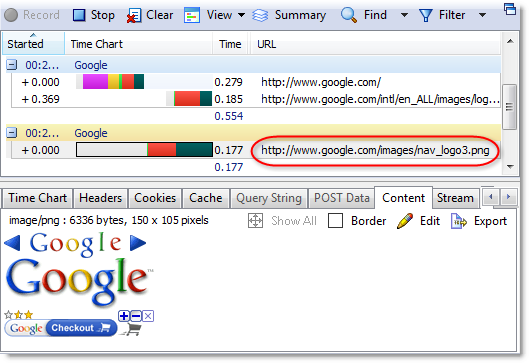
Hidden fields are used to maintain page-scoped variables that will be required by the server when the form is submitted, e.g. a user ID. They may also be injected by various web frameworks or server-side controls. One such example is the __VIEWSTATE field used by ASP.NET as shown below:
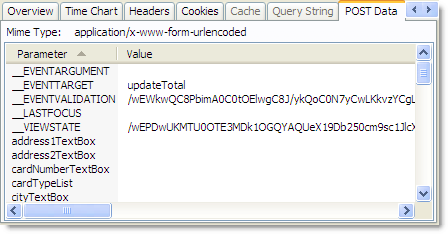
There are two reasons for doing this. Firstly it’s easier to have the state to hand (so to speak) in your page logic and secondly it often scales better across a web farm by keeping page scoped state within the page rather than fetching it from somewhere else like a database.
One way to reduce the amount of data in hidden fields is to only use a single key in a hidden form field. The key value is then used on the server to retrieve the data required to process the submitted page. This is exactly like the approach used to reduce the amount of cookie data. And like with cookies, reducing request transmission time in this way may have an impact on server-side performance and scalability.
Step 3: Avoid Verbose URLs
This is not the most important issue on the list, but it is still worth considering. In practice there are no ubiquitous limits on URL length, but most browsers will struggle with URLs longer than 4 KB – some may struggle at 1 KB or less. Remember that your URL will also end up in the referrer header of images and other embedded resources.
It’s usually the query string parameters that make a URL overly long. Again using Expedia as an example, you can see how many sites use these variables:
http://www.expedia.com/pub/agent.dll?qscr=fexp&flag=q&city1=lon&citd1=bos&date1=1/22/2008&time1=362&
date2=1/22/2008&time2=362&cAdu=1&cSen=&cChi=&cInf=&infs=2&
tktt=&trpt=2&ecrc=&eccn=&qryt=8&load=1&airp1=&dair1=&rdct=1&
rfrr=-429
In this case the URL is used to quickly pinpoint a results page for flights between ‘city1′ London (LON) and ‘city2′ Boston (BOS) on specific dates.
Encoding data like this in URLs does have certain advantages. If you bookmark or share the URL the same results will be displayed when the URL is next used. However, if the URL contains unused or redundant data it may be causing a significant increase in the amount of uploaded data.