Image Caching in Internet Explorer
![]() February 27, 2008 in
Caching , HttpWatch , Internet Explorer , Optimization
February 27, 2008 in
Caching , HttpWatch , Internet Explorer , Optimization
If you build, maintain or tune web sites you’ll know about the browser cache and how to control caching using HTTP response headers. We’ve talked about caching in several previous posts.
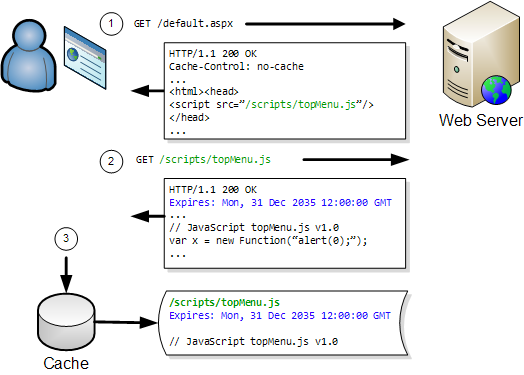
However, you may not be aware that IE uses two caches for holding images. First, there is the regular browser cache that keeps a copy of downloaded image files in your Temporary Internet Files folder. It’s this cache that can be controlled by HTTP response headers such as Cache-Control and Expires.
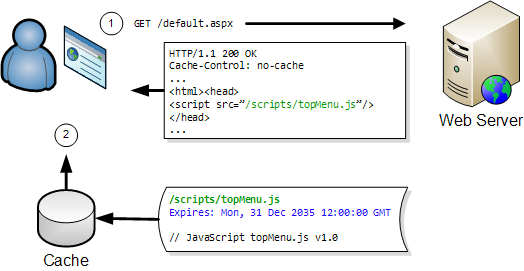
There is also an image cache that IE uses to hold recently used images in memory. The main difference between the image cache and the browser cache is:
- The image cache is never written to disk and is always emptied when IE closes
- The image cache contains an expanded, Windows bitmap version of GIF, JPG or PNG files
- HttpWatch does not record access to the image cache, unlike the 304 and (Cache) responses that you’ll see when IE reads content from the browser cache
The point of the image cache is that it can be used to quickly render images without taking the CPU hit required to convert them from their native compressed format into a Windows bitmap.
The only documentation about the image cache is the “Image Cache Limits” section of the registry settings for IE on Windows CE:
http://msdn2.microsoft.com/en-us/library/aa908131.aspx
Here’s the relevant section:
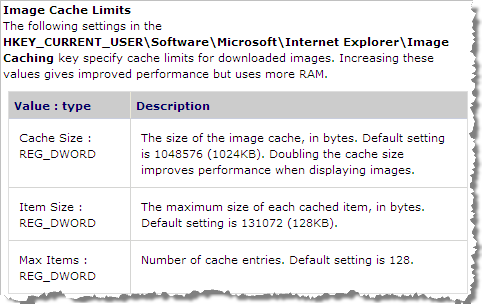
Although, these settings don’t work with IE 6 or 7 they do show that the image cache has limits on the size of images, the number of images cached and the maximum amount of memory that can be used. Limits like this have to be set because the expanded images can take up to 500% more memory than the original PNG, GIF or JPG format.
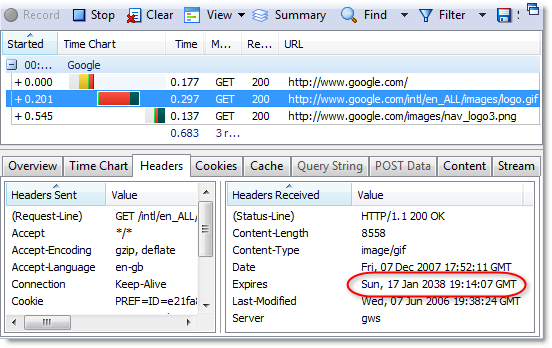
Let’s see the effect of the image cache by starting a new instance of IE and visting www.httpwatch.com:
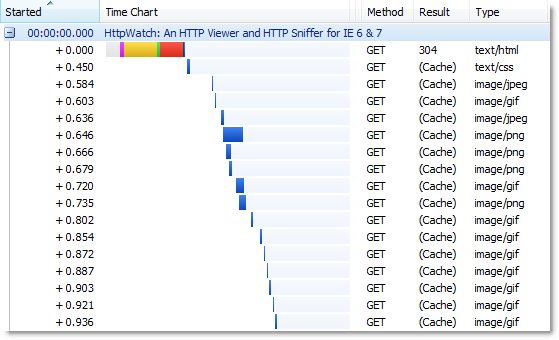
The (Cache) responses shown in HttpWatch indicate that the images on our home page were read from the browser cache. The image cache would have been empty at this point because IE had just started.
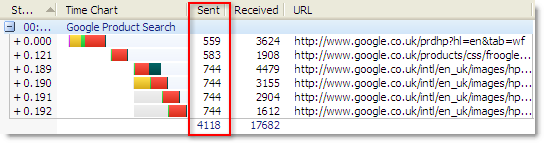
If you click on the Download tab and then click back on the Home page tab you’ll see that only two images are shown in the resulting HttpWatch trace:
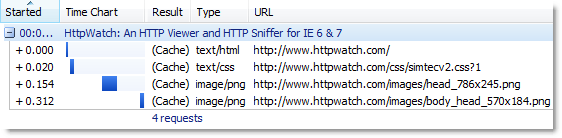
Clearly, all the images for the home page must have been loaded from somewhere because the page was correctly rendered, but only two images requests from the browser cache are seen in HttpWatch. This is because the other images were read from the image cache.
Why were two of the PNG files still read from the browser cache? These two images are the largest image files on the page and they would expand to approximately 500 KB and 300 KB if they were both placed in the image cache. They probably breached the maximum image size limit in the IE 7 image cache and were therefore not stored in their expanded form.
It’s also possible to see that the image cache has a limit on the number of images it stores. Try visiting ebay.com and then yahoo.com in the same browser window to load up the image cache. If you then go back to www.httpwatch.com you’ll see that all the images have been flushed out of the image cache and had to be reloaded from the browser cache.
So, to make effective use of the image cache in IE you should:
- Minimize the number of images that your site uses
- Avoid single images that might expand to more than approx 200 KB
Of course, you should always try to minimize the number of images to reduce the network round-trips when a browser first loads a page. A popular technique for doing this is to use CSS sprites to merge several images together and there are some great tools to help you create the compound image.
Be careful though, that you don’t run into item 2) by creating a single large image that is not loaded into the image cache. You would get the benefit of less round trips on an initial visit, but the rendering in IE might actually be slower because the image would have to expanded from the browser cache whenever it was re-displayed.