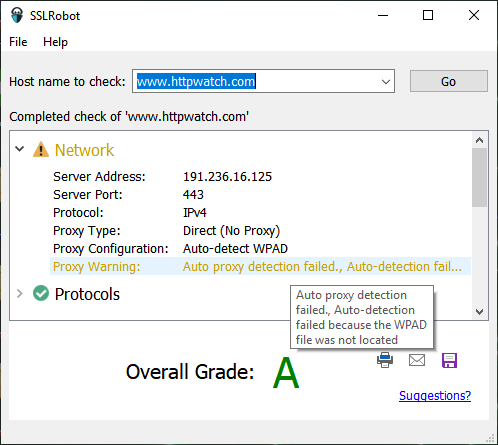
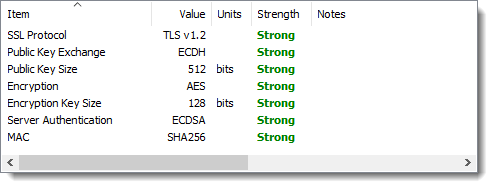
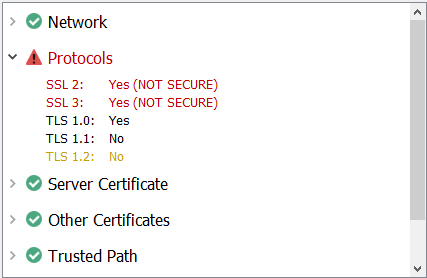
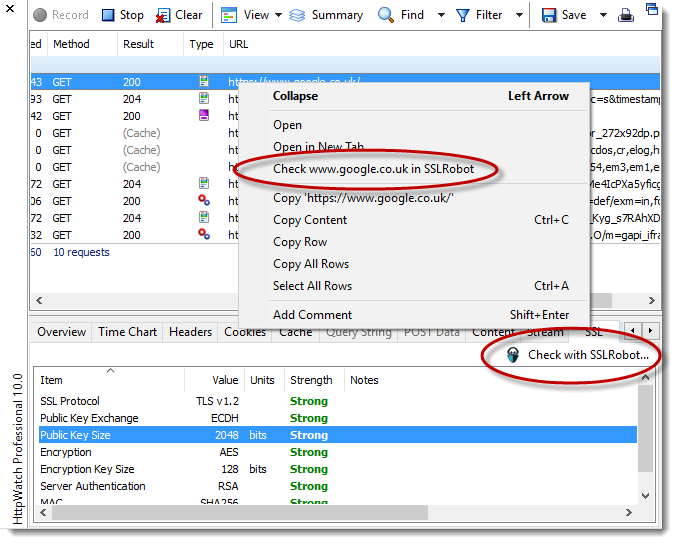
What’s New in Version 13.1?
HttpWatch 13.1 is now available for download and includes the following new features.
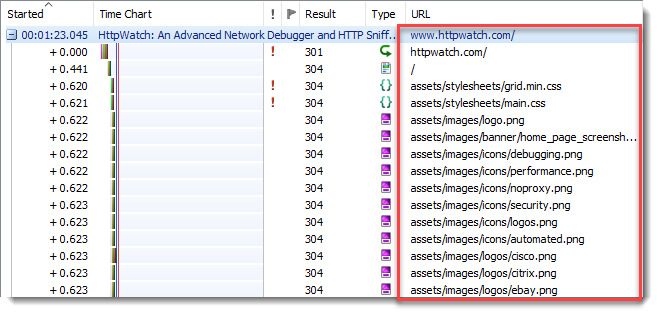
Improved Display of URLs
The page URL (including fragments) is now shown for each page group making it easier to debug Progressive Web Apps (PWAs) where URL fragments may be used for navigation. Also by default, URLs are displayed relative to the containing page and the HTTPS scheme prefix is hidden:
Insecure HTTP Warning Symbol
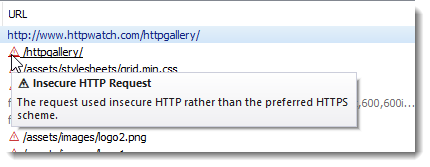
A red warning triangle is displayed next to insecure HTTP requests:
URL Display Options
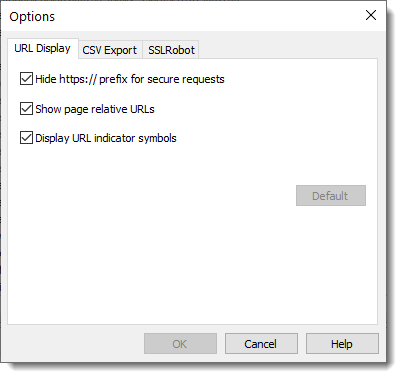
A new URL Display options tab can be used to configure how URLs are displayed:
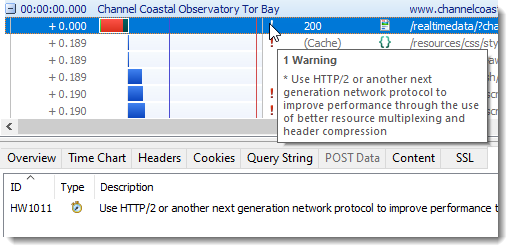
Warning Generated When HTTP/2 Not Used
A new warning (HW1011) highlights requests that did not use HTTP/2 (or a later network protocol) and therefore may not have optimal performance: