How to Automatically Install and Enable a Chrome Extension
The HttpWatch installer adds the HttpWatch extension to Chrome but the user needs to manually approve it before its first use:
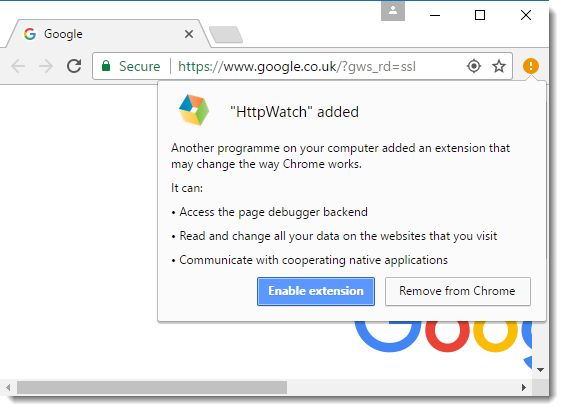
Our larger customers typically install HttpWatch through automated scripts using command line flags to silently run the installer. Unfortunately, the manual step shown above is still required on each PC before the user can access HttpWatch.
There is a way to force the installation of HttpWatch or any other Chrome extension using Chrome extension policies. The ExtensionInstallForcelist value specifies which extensions should be automatically installed and enabled from the Chrome Web Store. This value is stored in the registry in the following location for all users:
HKEY_LOCAL_MACHINE\Software\Policies\Google\Chrome\ExtensionInstallForcelist
or in this location for a single user:
HKEY_CURRENT_USER\SOFTWARE\Policies\Google\Chrome\ExtensionInstallForcelist
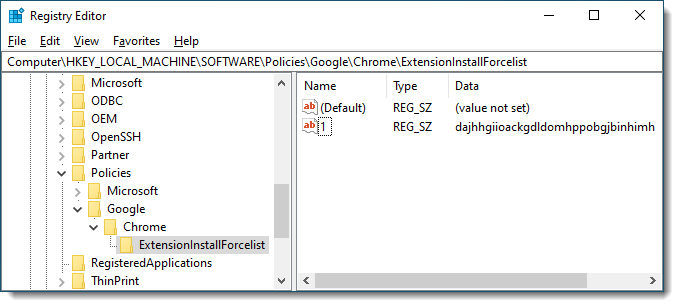
Each extension to be installed in this way must have a numbered value. For example, with HttpWatch the entry would be:
[HKEY_LOCAL_MACHINE\Software\Policies\Google\Chrome\ExtensionInstallForcelist] = "1"="dajhhgiioackgdldomhppobgjbinhimh"
In RegEdit it would look like this:
The next time Chrome restarts it will automatically download and enable the extension without requiring any manual intervention. An added advantage of doing this with HttpWatch is that no debugging banner is displayed in Chrome when HttpWatch is recording.
Microsoft Edge has a similar set of policies that can also be used to force the installation of an extension.