What’s New in HttpWatch 13.0?
HttpWatch 13 is now available for download and includes the following new features.
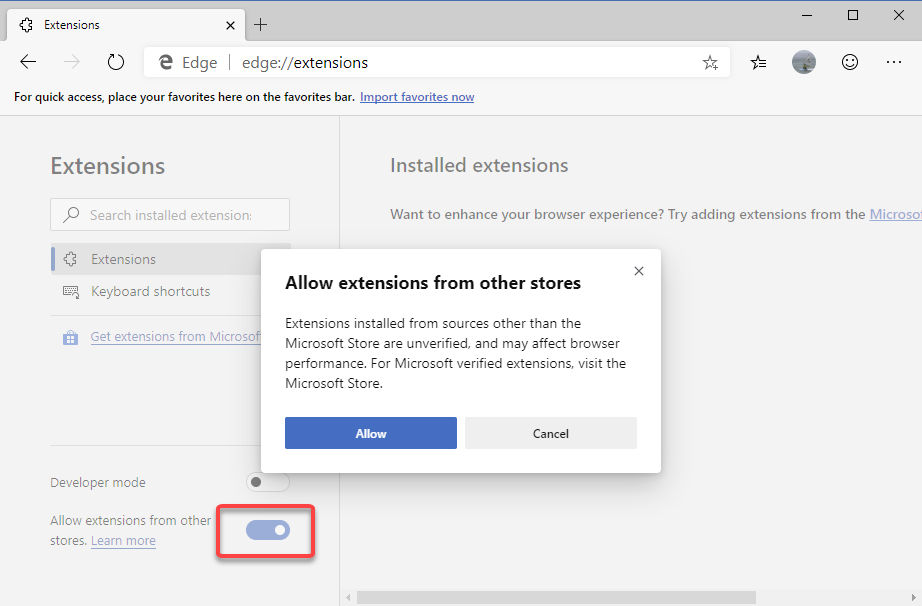
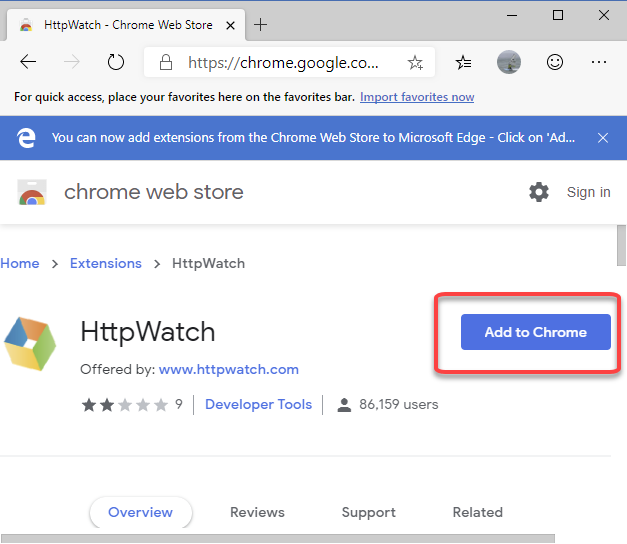
Fully Supports Microsoft Edge
HttpWatch now works with Microsoft Edge 80 or later using an extension hosted in the Microsoft Store:

The Edge support includes an automation class for controlling the HttpWatch Edge extension:
and a sample program for using Edge, Selenium and HttpWatch together.
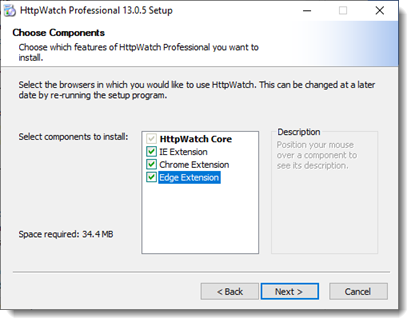
Enhanced Installer
You can now choose which browsers to use with HttpWatch when you run the installer. It is also possible to only install HttpWatch Studio if you just want to open existing HAR or HWL log files:
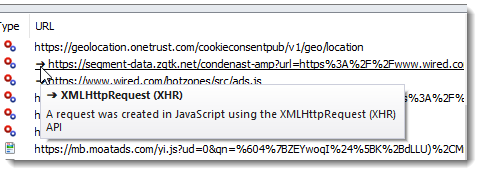
URL Indicator Symbols Show the use of Fetch and XmlHttpRequest APIs
In Chrome and Edge an arrow symbol next to a URL shows that a request was created using the XmlHttpRequest (XHR) API in Javascript:
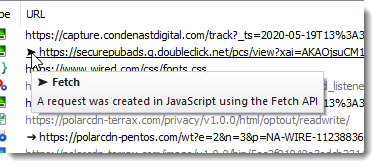
Or an arrow head symbol if the Fetch API was used:
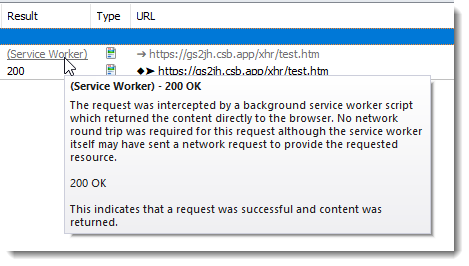
Displays Service Worker Activity
When a service worker script intercepts a request the Result now displays (Service Worker). The status code is available in the data tip or Overview Tab:
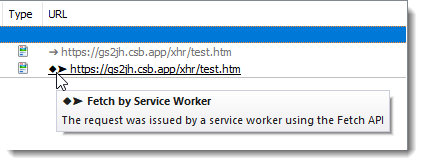
A diamond URL indicator is used to show the outgoing requests made by a service worker:
Supports Snapped Window Positions
HttpWatch now restores extension and log windows to their original position even if they were placed with the Windows snap feature:
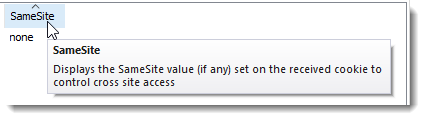
Displays SameSite Cookie Attribute
The cookie panel now displays the SameSite attribute for cookies received from the server:
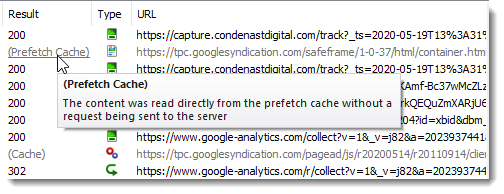
Shows The Use of the Memory and Prefetch Cache
The Result column in Chrome and Edge now shows whether the memory or prefetch cache was used:
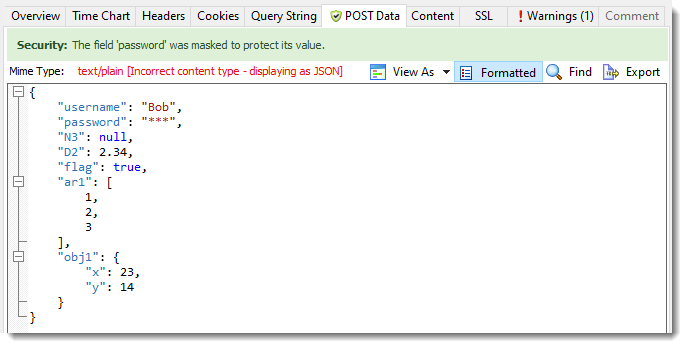
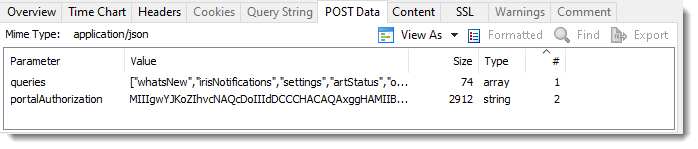
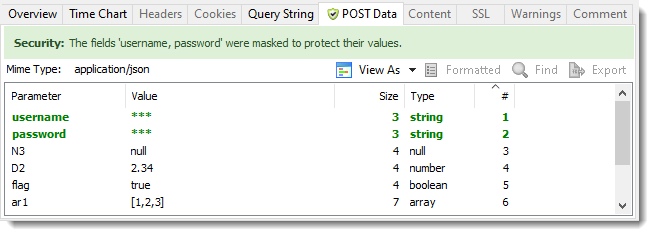
Detects The Use of JSON Without The Correct Content Type
HttpWatch now formats and applies password masking to JSON content even if the content type has been incorrectly set to a different format: